Archive
Two constructions
In the past two weeks I posted on the arXiv two very different papers. One is in Discrete Geometry (joint with Karim Adiprasito) and another is in Asymptotic Group Theory (joint with Martin Kassabov). Both are fundamentally combinatorial, resolve (or at least advance) some rather old open problems, and leave some room for future work. And both are completely constructive, in a way a combinatorialist would appreciate.
If there is any moral of these two completely unrelated research projects, it’s that explicit combinatorial constructions are underrated and understudied. This is easy to explain. The elegance in structural results can be delightful and they bring order to a small part of the mathematical universe and can serve as a foundation for future work.
In contrast, new constructions create a mess that cannot be easily explained away and it can take time until they become accepted as a useful tool in the area. This phenomenon is similar to disproving famous conjectures that we talked about in this old blog post. Potentially, there are many more explicit combinatorial constructions both in positive and negative direction. All for the better, of course.
Stellar subdivisions
The paper All triangulations have a common stellar subdivision is available here (see also Karim’s blog post). The results are very general, but new already in the plane for triangulations of convex polygons. Let me state the main theorem in that case to give you a flavor what’s going on.
Let Q be a convex polygon in the plane. A triangulation of Q is a subdivision (face to face partition) of Q into triangles. For example, here is a triangulation of a triangle.
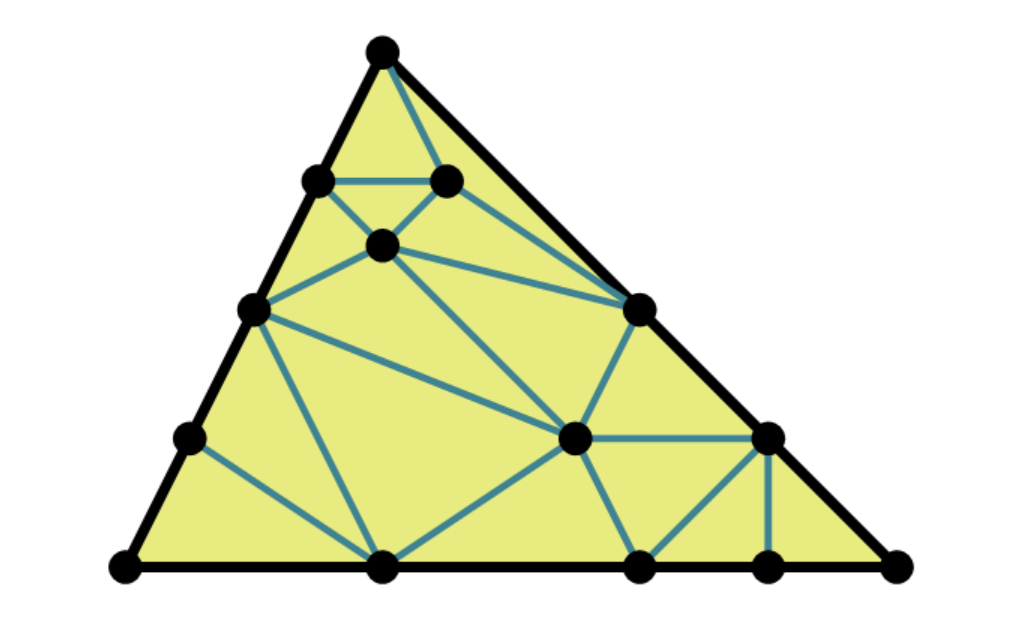
We now define stellar subdivisions as certain local transformations of triangulations. In the plane, there are two types: you can either place a new vertex inside the triangle and connect to vertices of the triangle, or you can place it on the edge and connect to vertices of triangles adjacent to this edge.
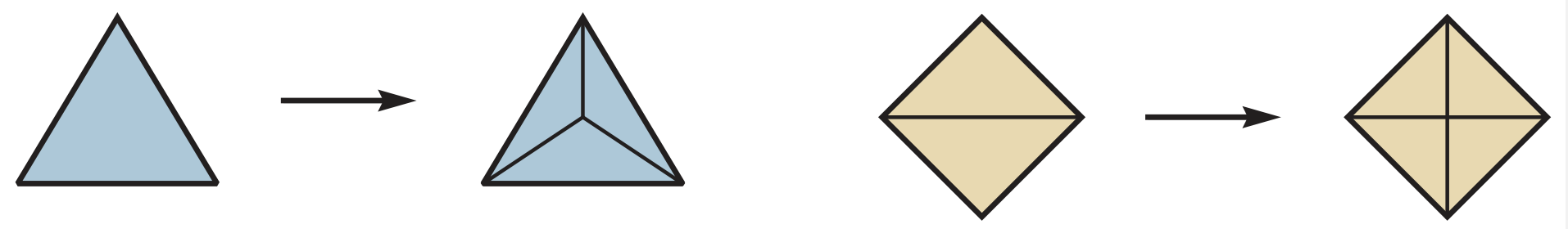
One can iterate such stellar subdivisions making triangulations more and more complicated, since at each step one new vertex is being added. If a triangulation C can be obtained from triangulations A and B by iterated stellar subdivisions, we say that A and B have a common subdivision C.
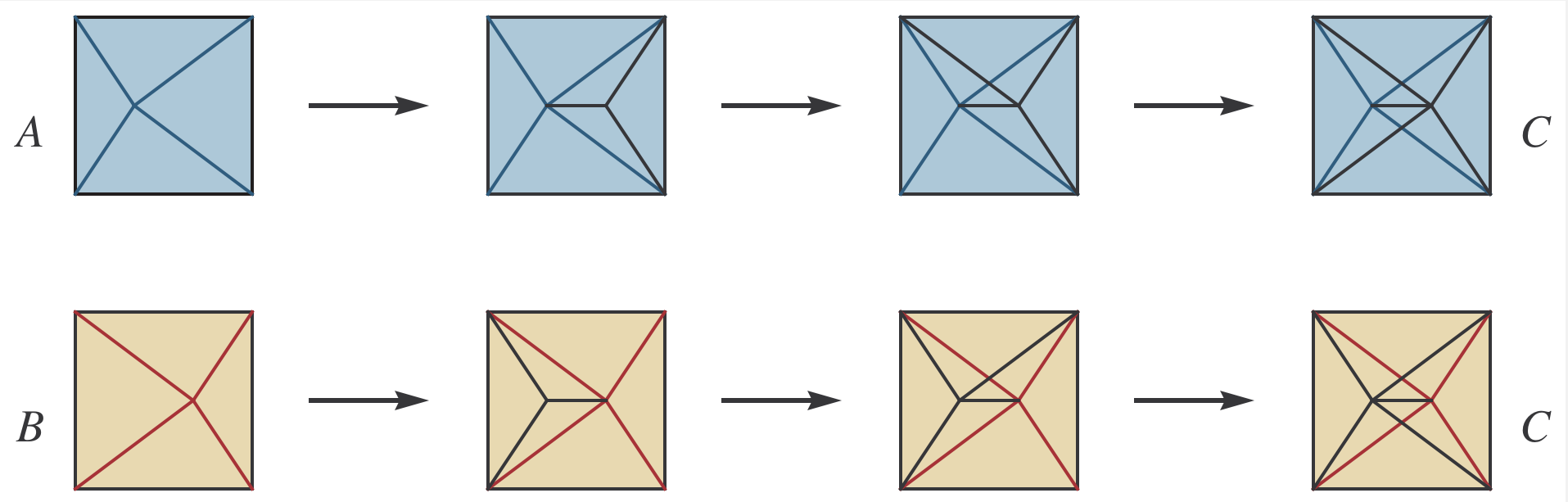
Theorem (Adiprasito-P.): Every two triangulations of a convex polygon in the plane have a common subdivision.
This may seem like a high school olympiad problem, and some day it probably will be. However, initially we thought this problem should have a negative answer. It was just too old and famous to have a positive solution, right? People must have tried everything, have they not? Well, I guess not.
In fact, it is well known and not very difficult to see that every two triangulations are connected by a sequence of stellar subdivisions and their inverses (in the plane, this was proved by Danilov in 1983, see refs in the paper). So the theorem really says that every two triangulations are connected by a sequence of stellar subdivisions followed by a sequence of inverse stellar subdivisions.
We give two closely related constructions in the paper: one that is more elementary and one that is less intuitive but is the starting point of a general construction (in a all dimensions). This resolves Oda’s (weighted) strong factorization conjecture. Another important consequence of our work is the proof of Alexander’s conjecture, which is essentially the same result but in topological setting.
The key open problem that’s left is the unweighted strong factorization conjecture, where the added points have additional constraints on their location (see Question 7.1 in the paper). It is unclear if one should believe in that conjecture at all, but our proof definitely breaks down.
Spectral radius
The paper Monotone parameters on Cayley graphs of finitely generated groups is available here. We obtain the main results about eight years ago, and only now got around to writing them. While writing, we generalized them to other what we call monotone parameters, but let me discuss only the spectral radius.
Let Γ=Cay(G,S) be a Cayley graph of an infinite group G with a symmetric generating set S. Let c(n) denote the number of words in S of length n equal to the identity e. Equivalently, c(n) is the number of loops in Γ of length n, starting and ending at e. The spectral radius ρ is defined as the limit

Famously, ρ=1 if an only if group G is amenable. There are several families of Cayley graphs where the spectral radius is known explicitly (free groups, free products of finite groups, etc.), but we really know very little:
Open Problem: What is the set X of all values of ρ over all pairs (G,S)? In particular, is X=(0,1]? If not, is X dense?
One version of the problem that I discuss in my ICM paper is this: Can one find an example of (G,S) such that ρ is transcendental? In this direction, Sarnak’s question (discussed e.g. here, Section G) asks whether the spectral radius for the surface group is transcendental? We give the following answer to the first question.
Theorem (Kassabov-P.) The set X of all spectral radii has cardinality of the continuum.
The result is proved by an explicit construction of a large family of 4-generated groups which gives an embedding of the Cantor set into X. Unfortunately, we are unable to give a single transcendental number which is a spectral radius of some group. One would think that there is some kind of Liouville number that comes out from the construction, and there surely is one, we just can’t give one explicitly.
The construction we give is based on another famous construction of the Grigorchuk group which disproved Milnor’s conjecture. This is a remarkable 4-generated group that has intermediate growth (both superpolynomial and subexponential). This group is the most famous example of a large uncountable family of such groups, and remains the source of many results and open problems.
While Grigorchuk’s groups are all amenable, of course, the flexibility of their structure allows one to decorate them. In our previous paper with Martin, we decorated them with finite expander quotients placed far apart to allow the oscillating intermediate growth. In this paper, we decorate them with nonamenable quotients to vary the spectral radii.
Of the many open problems that remain, let me single out one that is especially interesting from the computational combinatorics point of view. Recall that the Grigorchuk groups is not finitely presented, but is in fact recursively presented. Famously, it is not known whether there exist a finitely presented group of intermediate growth. Does there exists a finitely presented group with transcendental growth? Or at least recursively presented? We are nowhere close to resolving these questions.
UPDATE (Apr. 30, 2024). A finitely presented group with transcendental growth was just discovered by Corentin Bodart in this paper. Congratulations, Corentin!
The power of negative thinking: Combinatorial and geometric inequalities
It’s been awhile since I blogged about mathematics. You know why, of course — there are so many issues in the real world, the imaginary world is just not as relevant as it used to be. Well, at least that’s how I felt until now. But the latest paper we wrote with Swee Hong Chan was so much fun (and took so much effort), the wait is over. There is also some interesting backstory before we can state the result.
What is the inverse problem in Enumerative Combinatorics?
Before focusing on combinatorics, note that inverse problems are everywhere in mathematics. Sometimes they are obvious and stated as such, and sometimes we are so used to these problems we don’t think of them as inverse problems at all. You are probably thinking of major problems (both solved and unsolved), like the inverse Galois problem, Cauchy problem, Minkowski problem or the Alexandrov existence theorem. But really, even prime factorization, integration, taking logs and subtraction can be viewed this way. As I said — they are everywhere.
In Enumerative Combinatorics, a typical problem goes like this: given some set A, find the number N:=|A|. Finding a combinatorial interpretation is an inverse problem: given N, find A such that N=|A|. This might seem silly to an untrained eye: obviously, every nonnegative integer counts something. But it is completely normal to have constraints on the type of solution that you want — this case is no different.
Indeed, if you think about it, the direct problem is not all that well-defined either. For example, do you want an asymptotics or just some kind of bounds on N? Or maybe you want a closed formula? But what is a closed formula? Does it have to be a product formula, or some kind of summation will work? Can it be a multisum with both positive and negative terms? Or maybe you are ok with a closed formula for the generating function in case A=UAn? But what exactly is a closed formula for a GF? The list of questions goes on.
Five years ago, I discussed various different answers to these question in my ICM paper, with ideas goes back to Wilf’s beautiful paper (see also Stanley’s answer). If anything, the answers are not short and sometimes technical. Although my formulations are well-defined, positive results can be hard to prove, while negative results can be really hard to prove. Such is life, I suppose.
So what exactly is a combinatorial interpretation?
It is easy to go philosophical (as Rota does or I do on somewhat broader questions), but let’s focus on math here. I started thinking about the problem when I came to UCLA over twelve years ago, and struggled to find a good answer. I discussed the problem in my Notices paper when I finally made peace with the computational complexity approach. Of the multiple definitions, there is only one that is both convincing, workable and broad enough:
Combinatorial interpretation = #P
I explain the answer in my lengthy OPAC survey on the subject, and in my somewhat entertaining OPAC talk (slides). I have miles to say about this, maybe some other time.
To understand why I case, it’s worth thinking of the origin of the problem. Say, you have an inequality a ≥ b between number of certain combinatorial objects, where a=|A|, b=|B|. If you have a nice explicit injection φ : B → A, this gives a combinatorial interpretation for the defect (a–b) as the number of elements in A without a preimage. If φ and its inverse are computable in polynomial time, this shows that (a–b) counts the number of objects which can be certified to be correct in polynomial time. Thus, the definition of #P.
Now, as always happens in these cases, the reason for the definition is not to give a positive answer (“you know it when you see it” was a guiding principle for a long time), but to give a negative answer. What if many of these combinatorial interpretation problems Stanley discusses in his famous survey simply don’t have a solution? (see my OPAC survey linked above, and this MO discussion for the state of art).
To list my favorite open problem, do Kronecker coefficients g(λ,μ,ν) have a combinatorial interpretation? I don’t believe so, but to give a negative answer we need a definition. There is just no way around it. Note that we already have g(λ,μ,ν)= a(λ,μ,ν) – b(λ,μ,ν) for some numbers of combinatorial objects a and b (formally, these are #P functions). It is the injection that doesn’t seem to work. But why not?
Unfortunately, the universe of “not in #P” results is very small and includes only this FOCS paper with Christian Ikenmeyer and this SODA paper with Christian Ikenmeyer and Greta Panova. Simply put, such results are rare and hard to prove. Let me not explain them, but rather turn in the direction of my current work.
Poset inequalities
Since the inequalities like g(λ,μ,ν) ≥ 0 are so unapproachable in full generality, some four years ago I turned to inequalities on the number of linear extensions of finite posets. Many such inequalities are known in the literature, e.g. the XYZ inequality, the Sidorenko inequality, the Björner–Wachs inequality, etc. It is unclear whether the defect of the XYZ inequality has a combinatorial interpretation, but the other two certainly do (see our “Effective poset inequalities” paper with Swee Hong Chan and Greta Panova).
What we found most interesting and challenging, is the following remarkable Stanley’s inequality on the log-concavity of the number of certain linear extensions:
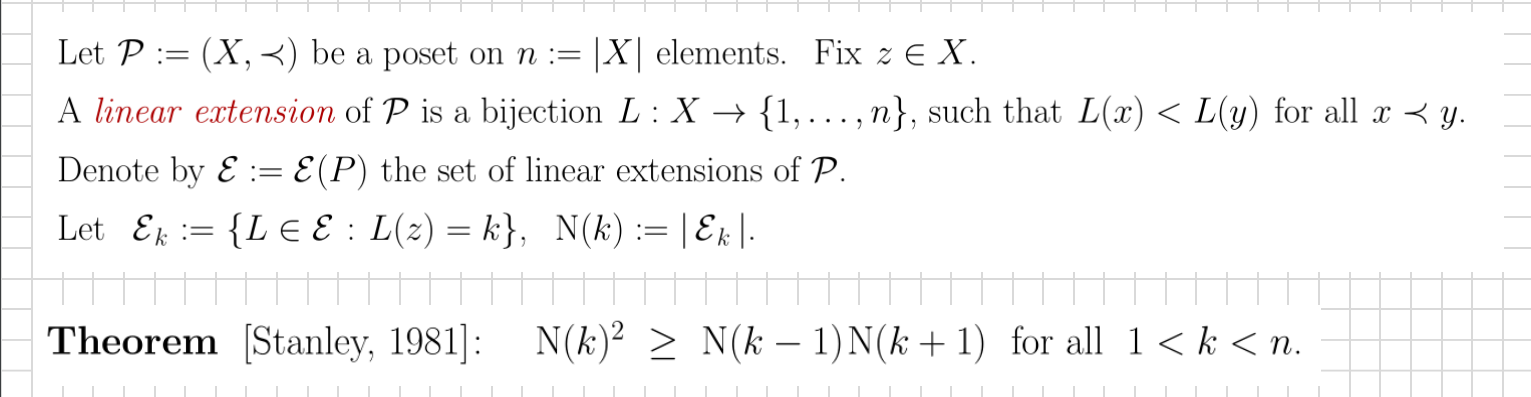
(this is a slide from my 2021 talk). In a remarkable breakthrough, Stanley resolved the Chung-Fishburn-Graham conjecture using the Alexandrov–Fenchel inequality (more on this later). What I was interesting in the following problem: Is the defect of Stanley’s inequality N(k)^2-N(k-1) N(k+1) in #P? This is still an open problem, and we don’t have tools to resolve it.
It gets worse: in an effort to show that this inequality is in #P, two years ago we introduced a whole new technology of combinatorial atlas. We used this technology to prove a lot new inequalities in this paper with Swee Hong Chan, including multivariate extensions of Stanley inequalities and correlation inequalities. We now know why this technology was never going to apply to the #P problem, but that’s all yet another story.
What we did in our new paper is attacked a similar problem for the generalized Stanley inequality, which has the same statement but with additional constraints that L(xi)=ci for all 1 ≤ i ≤ m, where xi are fixed poset elements and ci are fixed integers. Stanley derived the log-concavity of these more general numbers from the AF inequality in one big swoosh. In our paper, we prove:
Corollary 1.5. The defect of the generalized Stanley inequality is not in #P, for all m ≥ 2 (unless PH collapses to a finite level).
Curiously, in addition to a lot of poset theoretic technology we are using the Yao-Knuth theorem in number theory. Our main result is stronger:
Theorem 1.3. The equality cases of the generalized Stanley inequality are not in PH, for all m ≥ 2 (unless PH collapses to a finite level).
Clearly, if the defect was in #P, then the “defect =? 0″ is in coNP, and the “not in #P” result follows. The complexity theoretic idea of the proof is distilled in our companion paper where we explain why the coincidence problem for domino tilings in R3 is not in PH, and the same holds for many other hard combinatorial problems.
This underscores both the strength and the weakness of our approach. On the one hand, we prove a stronger result than we wanted. On the other hand, for m=0 it is known that the equality cases of the generalized Stanley inequality are in P. This is a remarkable result of Shenfeld and van Handel (actually, a consequence of the their remarkable theory). In fact, we reprove and generalize the result in our combinatorial atlas paper. In the new paper, we prove the m=1 version of this result, using a (also remarkable) followup paper by Ma and Shenfeld. We conjecture that m=2, the defect is already not in #P (Conjecture 10.2), but there seem to be difficult number theoretic obstacles to the proof.
In summary, we now know for sure that the defect of the generalized Stanley inequality does not have a combinatorial interpretation. In particular, there is no direct injective proof similar to that for the Sidorenko inequality, for example (cf. this old blog post). If you are deeply engaged with the subject (and why would you be, obviously?), you are happy. But if not — you probably shrug. Let me now explain why you should still care.
Geometric inequalities
It is rare when when you can honestly say this, but the geometric inequalities really do go back to antiquity (see e.g. here and there), when the isoperimetric inequality in the plane was first discovered. Of the numerous inequalities that followed, note the Brunn–Minkowski inequality and the Minkowski quadratic inequality (MQI) for three convex bodies in R3. These are all consequences of the Alexandrov–Fenchel inequality mentioned above. However, when it comes to equality conditions there is a bit of wrinkle.
For the isoperimetric inequality in the plane, the equality cases are obvious (discs), and there is an interesting history of proofs by symmetrization. For the BM inequality, the equality cases are homothetic convex bodies, but the proof is very far from obvious and requires the mixed volume machinery. For the MQI, the equality conditions were know only in some special cases, and resolved in full generality only recently by Shenfeld and van Handel.
For the AF inequality, the effort to understand the equality conditions goes back to A. D. Alexandrov, who found equality conditions in some cases:
Serious difficulties occur in determining the conditions for equality to hold in the general inequalities just derived. [Alexandrov, 1937]
In 1985, Rolf Schneider formulated a workable conjecture on the equality conditions, which remains out of reach in full generality. He made a strong case for the importance of the problem:
As [AF inequality] represents a classical inequality of fundamental importance and with many applications, the identification of the equality cases is a problem of intrinsic geometric interest. Without its solution, the Brunn–Minkowski theory of mixed volumes remains in an uncompleted state. [Schneider, 1994]
In the remarkable paper mentioned above, Shenfeld and van Handel resolved several special cases of the conjecture. Notably, they gave a complete characterization of the equality conditions for convex polytopes, in a sense of extracting all geometry from the problem, and stating the condition in terms of equality of certain mixed volumes. This is where we come in.
Equality cases of the AF inequality are not in PH
To understand the way Stanley derived his inequality from the AF inequality, it’s worth first explaining the connection to log-concavity:
Stanley considered sections P, Q of the order polytope associated with a given poset and concluded log-concavity for the numbers N(k) via a simple calculation.
Now, our “not in PH” theorem on the equality cases of Stanley’s inequality and this Stanley’s calculation imply that equality cases of the AF inequality are also not in PH (under the same complexity assumptions plus computational setup on how the polytopes are presented). In some sense, this says that the equality cases of the AF inequality can never be fully described, or at least the description by Shenfeld and van Handel is probably the best one can do.
In the spirit of the #P application, our result also implies, that there is unlikely to be a stability result for the AF inequality in full generality (in this sense), see Corollary 1.2 in the paper. Omitting precise statements and technicalities, let us only mention that Bonnesen’s inequality is a basic stability result which can be viewed as a sharp extension of the isoperimetric inequality, including the equality conditions. What we are saying is — don’t expect to ever see anything like that for the AF inequality (see the paper for details).
UPDATE (Feb. 7, 2024). The “m ≥ 6” was later improved to “m ≥ 2“, see our paper on the arXiv. See this video of my Oberwolfach talk on the subject. See also this blog post by Gil Kalai. Note: This paper was accepted to appear at STOC 2024.
The journal hall of shame
As you all know, my field is Combinatorics. I care about it. I blog about it endlessly. I want to see it blossom. I am happy to see it accepted by the broad mathematical community. It’s a joy to see it represented at (most) top universities and recognized with major awards. It’s all mostly good.
Of course, not everyone is on board. This is normal. Changing views is hard. Some people and institutions continue insisting that Combinatorics is mostly a trivial nonsense (or at least large parts of it). This is an old fight best not rehashed again.
What I thought I would do is highlight a few journals which are particularly hostile to Combinatorics. I also make some comments below.
Hall of shame
The list below is in alphabetical order and includes only general math journals.
(1) American Journal of Mathematics
The journal had a barely mediocre record of publishing in Combinatorics until 2008 (10 papers out of 6544, less than one per 12 years of existence, mostly in the years just before 2008). But then something snapped. Zero Combinatorics papers since 2009. What happened??
The journal keeps publishing in other areas, obviously. Since 2009 it published the total of 696 papers. And yet not a single Combinatorics paper was deemed good enough. Really? Some 10 years ago while writing this blog post I emailed the AJM Editor Christopher Sogge asking if the journal has a policy or an internal bias against the area. The editorial coordinator replied:
I spoke to an editor: the AJM does not have any bias against combinatorics. [2013]
You could’ve fooled me… Maybe start by admitting you have a problem.
(2) Cambridge Journal of Mathematics
This is a relative newcomer, established just ten years ago in 2013. CJM claims to:
publish papers of the highest quality, spanning the range of mathematics with an emphasis on pure mathematics.
Out of the 93 papers to date, it has published precisely Zero papers in Combinatorics. Yes, in Cambridge, MA which has the most active combinatorics seminar that I know (and used to co-organize twice a week). Perhaps, Combinatorics is not “pure” enough or simply lacks “papers of highest quality”.
Curiously, Jacob Fox is one of the seven “Associate Editors”. This makes me wonder about the CJM editorial policy, as in can any editor accept any paper they wish or the decision has to made by a majority of editors? Or, perhaps, each paper is accepted only by a unanimous vote? And how many Combinatorics papers were provisionally accepted only to be rejected by such a vote of the editorial board? Most likely, we will never know the answers…
The journal also had a mediocre record in Combinatorics until 2006 (12 papers out of 2661). None among the last 1172 papers (since 2007). Oh, my… I wrote in this blog post that at least the journal is honest about Combinatorics being low priority. But I think it still has no excuse. Read the following sentence on their front page:
Papers on other topics are welcome if they are of broad interest.
So, what happened in 2007? Papers in Combinatorics suddenly lost broad interest? Quanta Magazine must be really confused by this all…
(4) Publications Mathématiques de l’IHÉS
Very selective. Naturally. Zero papers in Combinatorics. Yes, since 1959 they published the grand total of 528 papers. No Combinatorics papers made the cut. I had a very limited interaction with the journal when I submitted my paper which was rejected immediately. Here is what I got:
Unfortunately, the journal has such a severe backlog that we decided at the last meeting of the editorial board not to take any new submissions for the next few months, except possibly for the solution of a major open problem. Because of this I prefer to reject you paper right now. I am sorry that your paper arrived during that period. [2015]
I am guessing the editor (very far from my area) assumed that the open problem that I resolved in that paper could not possibly be “major” enough. Because it’s in Combinatorics, you see… But whatever, let’s get back to ZERO. Really? In the past 50 years Paris has been a major research center in my area, one of the best places to do Enumerative, Asymptotics and Algebraic Combinatorics. And none of that work was deemed worthy by this venerable journal??
Note: I used this link for a quick guide to top journals. It’s biased, but really any other ranking would work just as well. I used the MathSciNet to determine whether papers are in Combinatorics (search for MSC Primary = 05)
How should we understand this?
It’s all about making an effort. Some leading general journals like Acta, Advances, Annals, Duke, Inventiones, JAMS, JEMS, Math. Ann., Math. Z., etc. found a way to attract and publish Combinatorics papers. Mind you they publish very few papers in the area, but whatever biases they have, they apparently want to make sure combinatorialists would consider sending their best work to these journals.
The four hall of shamers clearly found a way to repel papers in Combinatorics, whether by exhibiting an explicit bias, not having a combinatorialist on the editorial board, never encouraging best people in the area to submit, or using random people to give “quick opinions” on work far away from their area of expertise.
Most likely, there are several “grandfathered areas” in each journal, so with the enormous growth of submissions there is simply no room for other areas. Here is a breakdown of the top five areas in Publ. Math. IHES, helpfully compiled by ZbMATH (out of 528, remember?):

Of course, for the CJM, the whole “grandfathered areas” reasoning does not apply. Here is their breakdown of the top five areas (out of 93). See any similarities? Looks like this is a distribution of areas that the editors think are “very very important”:

When 2/3 of your papers are in just two areas, “spanning the range of mathematics” this journal is not. Of course, it really doesn’t matter how the four hall of shamers managed to achieve their perfect record for so many years — the results speak for themselves.
What should you do about it?
Not much, obviously, unless you are an editor in either of these four journals. Please don’t boycott them — it’s counterproductive and they are already boycotting you. If you work in Combinatorics, you should consider submitting your best work there, especially if you have tenure and have nothing to lose by waiting. This was the advice I gave vis-à-vie the Annals and it still applies.
But perhaps you can also shame these journals. This was also my advice on MDPI Mathematics. Here some strategy is useful, so perhaps do this. Any time you are asked for a referee report or for a quick opinion, ask the editor: Does your journal have a bias against Combinatorics? If they want your help they will say “No”. If you write a positive opinion or a report, follow up and ask if the paper is accepted. If they say “No”, ask if they still believe the journal has no bias. Aim to exhaust them!
More broadly, tell everyone you know that these four journals have an anti-Combinatorics bias. As I quoted before, Noga Alon thinks that “mathematics should be considered as one unit“. Well, as long as these journals don’t publish in Combinatorics, I will continue to disagree, and so should you. Finally, if you know someone on the editorial board of these four journals, please send them a link to this blog post and ask to write a comment. We can all use some explanation…
Innovation anxiety
I am on record of liking the status quo of math publishing. It’s very far from ideal as I repeatedly discuss on this blog, see e.g. my posts on the elitism, the invited issues, the non-free aspect of it in the electronic era, and especially the pay-to-publish corruption. But overall it’s ok. I give it a B+. It took us about two centuries to get where we are now. It may take us awhile to get to an A.
Given that there is room for improvement, it’s unsurprising that some people make an effort. The problem is that their efforts be moving us in the wrong direction. I am talking specifically about two ideas that frequently come up by people with best intensions: abolishing peer review and anonymizing the author’s name at the review stage. The former is radical, detrimental to our well being and unlikely to take hold in the near future. The second is already here and is simply misguided.
Before I take on both issues, let me take a bit of a rhetorical detour to make a rather obvious point. I will be quick, I promise!
Don’t steal!
Well, this is obvious, right? But why not? Let’s set all moral and legal issues aside and discuss it as adults. Why should a person X be upset if Y stole an object A from Z? Especially if X doesn’t know either Y or Z, and doesn’t really care who A should belong to. Ah, I see you really don’t want to engage with the issue — just like me you already know that this is appalling (and criminal, obviously).
However, if you look objectively at the society we live in, there is clearly some gray area. Indeed, some people think that taxation is a form of theft (“taking money by force”, you see). Millions of people think that illegally downloading movies is not stealing. My university administration thinks stealing my time making me fill all kinds of forms is totally kosher. The country where I grew up in was very proud about the many ways it stole my parents’ rights for liberty and the pursuit of happiness (so that they could keep their lives). The very same country thinks it’s ok to invade and steal territory from a neighboring country. Apparently many people in the world are ok with this (as in “not my problem”). Not comparing any of these, just challenging the “isn’t it obvious” premise.
Let me give a purely American answer to the “why not” question. Not the most interesting or innovative argument perhaps, but most relevant to the peer review discussion. Back in September 1789, Thomas Jefferson was worried about the constitutional precommitment. Why not, he wondered, have a revolution every 19 years, as a way not to burden future generations with rigid ideas from the past?
In February 1790, James Madison painted a grim picture of what would happen: “most of the rights of property would become absolutely defunct and the most violent struggles be generated” between property haves and have-nots, making remedy worse than the disease. In particular, allowing theft would be detrimental to continuing peaceful existence of the community (duh!).
In summary: a fairly minor change in the core part of the moral code can lead to drastic consequences.
Everyone hates peer review!
Indeed, I don’t know anyone who succeeded in academia without a great deal of frustration over the referee reports, many baseless rejections from the journals, or without having to spend many hours (days, weeks) writing their own referee reports. It’s all part of the job. Not the best part. The part well hidden from outside observers who think that professors mostly teach or emulate a drug cartel otherwise.
Well, the help is on the way! Every now and then somebody notably comes along and proposes to abolish the whole thing. Here is one, two, three just in the last few years. Enough? I guess not. Here is the most recent one, by Adam Mastroianni, twitted by Marc Andreessen to his 1.1 million followers.
This is all laughable, right? Well, hold on. Over the past two weeks I spoke to several well known people who think that abolishing peer review would make the community more equitable and would likely foster the innovation. So let’s address these objections seriously, point by point, straight from Mastroianni’s article.
(1) “If scientists cared a lot about peer review, when their papers got reviewed and rejected, they would listen to the feedback, do more experiments, rewrite the paper, etc. Instead, they usually just submit the same paper to another journal.” Huh? The same level journal? I wish…
(2) “Nobody cares to find out what the reviewers said or how the authors edited their paper in response” Oh yes, they do! Thus multiple rounds of review, sometimes over several years. Thus a lot of frustration. Thus occasional rejections after many rounds if the issue turns out non-fixable. That’s the point.
(3) “Scientists take unreviewed work seriously without thinking twice.” Sure, why not? Especially if they can understand the details. Occasionally they give well known people benefit of the doubt, at least for awhile. But then they email you and ask “Is this paper ok? Why isn’t it published yet? Are there any problems with the proof?” Or sometimes some real scrutiny happens outside of the peer review.
(4) “A little bit of vetting is better than none at all, right? I say: no way.” Huh? In math this is plainly ridiculous, but the author is moving in another direction. He supports this outrageous claim by saying that in biomedical sciences the peer review “fools people into thinking they’re safe when they’re not. That’s what our current system of peer review does, and it’s dangerous.” Uhm. So apparently Adam Mastroianni thinks if you can’t get 100% certainty, it’s better to have none. I feel like I’ve heard the same sentiment form my anti-masking relatives.
Obviously, I wouldn’t know and honestly couldn’t care less about how biomedical academics do research. Simply put, I trust experts in other fields and don’t think I know better than them what they do, should do or shouldn’t do. Mastroianni uses “nobody” 11 times in his blog post — must be great to have such a vast knowledge of everyone’s behavior. In any event, I do know that modern medical advances are nothing short of spectacular overall. Sounds like their system works really well, so maybe let them be…
The author concludes by arguing that it’s so much better to just post papers on the arXiv. He did that with one paper, put some jokes in it and people wrote him nice emails. We are all so happy for you, Adam! But wait, who says you can’t do this with all your papers in parallel with journal submissions? That’s what everyone in math does, at least the arXiv part. And if the journals where you publish don’t allow you to do that, that’s a problem with these specific journals, not with the whole peer review.
As for the jokes — I guess I am a mini-expert. Many of my papers have at least one joke. Some are obscure. Some are not funny. Some are both. After all, “what’s life without whimsy“? The journals tend to be ok with them, although some make me work for it. For example, in this recent paper, the referee asked me to specifically explain in the acknowledgements why am I thankful to Jane Austen. So I did as requested — it was an inspiration behind the first sentence (it’s on my long list of starters in my previous blog post). Anyway, you can do this, Adam! I believe in you!
Everyone needs peer review!
Let’s try to imagine now what would happen if the peer review is abolished. I know, this is obvious. But let’s game it out, post-apocaliptic style.
(1) All papers will be posted on the arXiv. In a few curious cases an informal discussion will emerge, like this one about this recent proof of the four color theorem. Most paper will be ignored just like they are ignored now.
(2) Without a neutral vetting process the journals will turn to publishing “who you know”, meaning the best known and best connected people in the area as “safe bets” whose work was repeatedly peer reviewed in the past. Junior mathematicians will have no other way to get published in leading journals without collaboration (i.e. writing “joint papers”) with top people in the area.
(3) Knowing that their papers won’t be refereed, people will start making shortcuts in their arguments. Soon enough some fraction will turn up unsalvageable incorrect. Embarrassments like the ones discussed in this page will become a common occurrence. Eventually the Atiyah-style proofs of famous theorems will become widespread confusing anyone and everyone.
(4) Granting agencies will start giving grants only to the best known people in the area who have most papers in best known journals (if you can peer review papers, you can’t expect to peer review grant proposals, right?) Eventually they will just stop, opting to give more money to best universities and institutions, in effect outsourcing their work.
(5) Universities will eventually abolish tenure as we know it, because if anyone is free to work on whatever they want without real rewards or accountability, what’s the point of tenure protection? When there are no objective standards, in the university hiring the letters will play the ultimate role along with many biases and random preferences by the hiring committees.
(6) People who work in deeper areas will be spending an extraordinary amount of time reading and verifying earlier papers in the area. Faced with these difficulties graduate students will stay away from such areas opting for more shallow areas. Eventually these areas will diminish to the point of near-extinsion. If you think this is unlikely, look into post-1980 history of finite group theory.
(7) In shallow areas, junior mathematicians will become increasingly more innovative to avoid reading older literature, but rather try to come up with a completely new question or a new theory which can be at least partially resolved on 10 pages. They will start running unrefereed competitive conferences where they will exhibit their little papers as works of modern art. The whole of math will become subjective and susceptible to fashion trends, not unlike some parts of theoretical computer science (TCS).
(8) Eventually people in other fields will start saying that math is trivial and useless, that everything they do can be done by an advanced high schooler in 15 min. We’ve seen this all before, think candid comments by Richard Feynman, or these uneducated proclamations by this blog’s old villain Amy Wax. In regards to combinatorics, such views were prevalent until relatively recently, see my “What is combinatorics” with some truly disparaging quotations, and this interview by László Lovász. Soon after, everyone (physics, economics, engineering, etc.) will start developing their own kind of math, which will be the end of the whole field as we know it.
…
(100) In the distant future, after the human civilization dies and rises up again, historians will look at the ruins of this civilization and wonder what happened? They will never learn that’s it’s all started with Adam Mastroianni when he proclaimed that “science must be free“.
Less catastrophic scenarios
If abolishing peer review does seem a little farfetched, consider the following less drastic measures to change or “improve” peer review.
(i) Say, you allow simultaneous submissions to multiple journals, whichever accepts first gets the paper. Currently, the waiting time is terribly long, so one can argue this would be an improvement. In support of this idea, one can argue that in journalism pitching a story to multiple editors is routine, that job applications are concurrent to all universities, etc. In fact, there is even an algorithm to resolve these kind of situations successfully. Let’s game this out this fantasy.
The first thing that would happen is that journals would be overwhelmed with submissions. The referees are already hard to find. After the change, they would start refusing all requests since they would also be overwhelmed with them and it’s unclear if the report would even be useful. The editors would refuse all but a few selected papers from leading mathematicians. Chat rooms would emerge in the style “who is refereeing which paper” (cf. PubPeer) to either collaborate or at least not make redundant effort. But since it’s hard to trust anonymous claims “I checked and there are no issues with Lemma 2 in that paper” (could that be the author?), these chats will either show real names thus leading to other complications (see below), or cease to exist.
Eventually the publishers will start asking for a signed official copyright transfer “conditional on acceptance” (some already do that), and those in violation will be hit with lawsuits. Universities will change their faculty code of conduct to include such copyright violations as a cause for dismissal, including tenure removal. That’s when the practice will stop and be back to normal, at great cost obviously.
(ii) Non-anonymizing referees is another perennial idea. Wouldn’t it be great if the referees get some credit for all the work that they do (so they can list it on their CVs). Even better if their referee report is available to the general public to read and scrutinize, etc. Win-win-win, right?
No, of course not. Many specialized sub-areas are small so it is hard to find a referee. For the authors, it’s relatively easy to guess who the referees are, at least if you have some experience. But there is still this crucial ambiguity as in “you have a guess but you don’t know for sure” which helps maintain friendship or at least collegiality with those who have written a negative referee report. You take away this ambiguity, and everyone will start refusing refereeing requests. Refereeing is hard already, there is really no need to risk collegial relationships as a result, especially in you are both going to be working the area for years or even decades to come.
(iii) Let’s pay the referees! This is similar but different from (ii). Think about it — the referees are hard to find, so we need to reward them. Everyone know that when you pay for something, everyone takes this more seriously, right? Ugh. I guess I have some new for you…
Think it over. You got a technical 30 page paper to referee. How much would you want to get paid? You start doing a mental calculation. Say, at a very modest $100/hr it would take you maybe 10-20 hours to write a thorough referee report. That’s $1-2K. Some people suggest $50/hr but that was before the current inflation. While I do my own share of refereeing, personally, I would charge more per hour as I can get paid better doing something else (say, teach our Summer school). For a traditional journal to pay this kind of money per paper is simply insane. Their budgets are are relatively small, let me spare you the details.
Now, who can afford that kind of money? Right — we are back to the open access journals who would pass the cost to the authors in the form of an APC. That’s when the story turn from bad to awful. For that kind of money the journals would want a positive referee report since rejected authors don’t pay. If you are not willing to play ball and give them a positive report, they will stop inviting you to referee, leading to more even corruption these journals have in the form of pay-to-publish.
You can probably imagine that this won’t end well. Just talk to medical or biological scientists who grudgingly pays to Nature or Science about 3K from their grants (which are much larger than ours). The pay because they have to, of course, and if they bulk they might not get a new grant setting back their career.
Double blind refereeing
In math, this means that the authors’ names are hidden from referees to avoid biases. The names are visible to the editors, obviously, to prevent “please referee your own paper” requests. The authors are allowed to post their papers on their websites or the arXiv, where it could be easily found by the title, so they don’t suffer from anxieties about their career or competitive pressures.
Now, in contrast with other “let’s improve the peer review” ideas, this is already happening. In other fields this has been happening for years. Closer to home, conferences in TCS have long resisted going double blind, but recently FOCS 2022, SODA 2023 and STOC 2023 all made the switch. Apparently they found Boaz Barak’s arguments unpersuasive. Well, good to know.
Even closer to home, a leading journal in my own area, Combinatorial Theory, turned double blind. This is not a happy turn of event, at least not from my perspective. I published 11 papers in JCTA, before the editorial board broke off and started CT. I have one paper accepted at CT which had to undergo the new double blind process. In total, this is 3 times as many as any other journal where I published. This was by far my favorite math journal.
Let’s hear from the journal why they did it (original emphasis):
The philosophy behind doubly anonymous refereeing is to reduce the effect of initial impressions and biases that may come from knowing the identity of authors. Our goal is to work together as a combinatorics community to select the most impactful, interesting, and well written mathematical papers within the scope of Combinatorial Theory.
Oh, sure. Terrific goal. I did not know my area has a bias problem (especially compared to many other areas), but of course how would I know?
Now, surely the journal didn’t think this change would be free? The editors must have compared pluses and minuses, and decided that on balance the benefits outweigh the cost, right? The journal is mum on that. If any serious discussion was conducted (as I was told), there is no public record of it. Here is what the journal says how the change is implemented:
As a referee, you are not disqualified to evaluate a paper if you think you know an author’s identity (unless you have a conflict of interest, such as being the author’s advisor or student). The journal asks you not to do additional research to identify the authors.
Right. So let me try to understand this. The referee is asked to make a decision whether to spend upwards of 10-20 hours on the basis of the first impression of the paper and without knowledge of the authors’ identity. They are asked not to google the authors’ names, but are ok if you do because they can’t enforce this ethical guideline anyway. So let’s think this over.
Double take on double blind
(1) The idea is so old in other sciences, there is plenty of research on its relative benefits. See e.g. here, there or there. From my cursory reading, it seems, there is a clear evidence of a persistent bias based on the reputation of educational institution. Other biases as well, to a lesser degree. This is beyond unfortunate. Collectively, we have to do better.
(2) Peer reviews have very different forms in different sciences. What works in some would not necessarily would work in others. For example, TCS conferences never really had a proper refereeing process. The referees are given 3 weeks to write an opinion of the paper based on the first 10 pages. They can read the proofs beyond the 10 pages, but don’t have to. They write “honest” opinions to the program committee (invisible to the authors) and whatever they think is “helpful” to the authors. Those of you outside of TCS can’t even imagine the quality and biases of these fully anonymous opinions. In recent years, the top conferences introduced the rebuttal stage which is probably helpful to avoid random superficial nitpicking at lengthy technical arguments.
In this large scale superficial setting with rapid turnover, the double blind refereeing is probably doing more good than bad by helping avoid biases. The authors who want to remain anonymous can simply not make their papers available for about three months between the submission and the decision dates. The conference submission date is a solid date stamp for them to stake the result, and three months are unlikely to make major change to their career prospects. OTOH, the authors who want to stake their reputation on the validity of their technical arguments (which are unlikely to be fully read by the referees) can put their papers on the arXiv. All in all, this seems reasonable and workable.
(3) The journal process is quite a bit longer than the conference, naturally. For example, our forthcoming CT paper was submitted on July 2, 2021 and accepted on November 3, 2022. That’s 16 months, exactly 490 days, or about 20 days per page, including the references. This is all completely normal and is nobody’s fault (definitely not the handling editor’s). In the meantime my junior coauthor applied for a job, was interviewed, got an offer, accepted and started a TT job. For this alone, it never crossed our mind not to put the paper on the arXiv right away.
Now, I have no doubt that the referee googled our paper simply because in our arguments we frequently refer our previous papers on the subject for which this was a sequel (er… actually we refer to some [CPP21a] and [CPP21b] papers). In such cases, if the referee knows that the paper under review is written by the same authors there is clearly more confidence that we are aware of the intricate parts of our own technical details from the previous paper. That’s a good thing.
Another good thing to have is the knowledge that our paper is surviving public scrutiny. Whenever issues arise we fix them, whenever some conjecture are proved or refuted, we update the paper. That’s a normal academic behavior no matter what Adam Mastroianni says. Our reputation and integrity is all we have, and one should make every effort to maintain it. But then the referee who has been procrastinating for a year can (and probably should) compare with the updated version. It’s the right thing to do.
Who wants to hide their name?
Now that I offered you some reasons why looking for paper authors is a good thing (at least in some cases), let’s look for negatives. Under what circumstances might the authors prefer to stay anonymous and not make their paper public on the arXiv?
(a) Junior researchers who are afraid their low status can reduce their chances to get accepted. Right, like graduate students. This will hurt them both mathematically and job wise. This is probably my biggest worry that CT is encouraging more such cases.
(b) Serial submitters and self-plagiarists. Some people write many hundreds of papers. They will definitely benefit from anonymity. The editors know who they are and that their “average paper” has few if any citations outside of self-citations. But they are in a bind — they have to be neutral arbiters and judge each new paper independently of the past. Who knows, maybe this new submission is really good? The referees have no such obligation. On the contrary, they are explicitly asked to make a judgement. But if they have no name to judge the paper by, what are they supposed to do?
Now, this whole anonymity thing is unlikely to help serial submitters at CT, assuming that the journal standards remain high. Their papers will be rejected and they will move on, submitting down the line until they find an obscure enough journal that will bite. If other, somewhat less selective journals adopt the double blind review practice, this could improve their chances, however.
For CT, the difference is that in the anonymous case the referees (and the editors) will spend quite a bit more time per paper. For example, when I know that the author is a junior researcher from a university with limited access to modern literature and senior experts, I go out of my way to write a detailed referee report to help the authors, suggest some literature they are missing or potential directions for their study. If this is a serial submitter, I don’t. What’s the point? I’ve tried this a few times, and got the very same paper from another journal next week. They wouldn’t even fix the typos that I pointed out, as if saying “who has the time for that?” This is where Mastroianni is right: why would their 234-th paper be any different from 233-rd?
(c) Cranks, fraudsters and scammers. The anonymity is their defense mechanism. Say, you google the author and it’s Dănuț Marcu, a serial plagiarist of 400+ math papers. Then you look for a paper he is plagiarizing from and if successful making efforts to ban him from your journal. But if the author is anonymous, you try to referee. There is a very good chance you will accept since he used to plagiarize good but old and somewhat obscure papers. So you see — the author’s identity matters!
Same with the occasional zero-knowledge (ZK) aspirational provers whom I profiled at the end of this blog post. If you are an expert in the area and know of somebody who has tried for years to solve a major conjecture producing one false or incomplete solution after another, what do you do when you see a new attempt? Now compare with what you do if this paper is by anonymous? Are you going to spend the same effort effort working out details of both papers? Wouldn’t in the case of a ZK prover you stop when you find a mistake in the proof of Lemma 2, while in the case of a genuine new effort try to work it out?
In summary: as I explained in my post above, it’s the right thing to do to judge people by their past work and their academic integrity. When authors are anonymous and cannot be found, the losers are the most vulnerable, while the winners are the nefarious characters. Those who do post their work on the arXiv come out about even.
Small changes can make a major difference
If you are still reading, you probably think I am completely 100% opposed to changes in peer review. That’s not true. I am only opposed to large changes. The stakes are just too high. We’ve been doing peer review for a long time. Over the decades we found a workable model. As I tried to explain above, even modest changes can be detrimental.
On the other hand, very small changes can be helpful if implemented gradually and slowly. This is what TCS did with their double blind review and their rebuttal process. They started experimenting with lesser known and low stakes conferences, and improved the process over the years. Eventually they worked out the kinks like COI and implemented the changes at top conferences. If you had to make changes, why would you start with a top journal in the area??
Let me give one more example of a well meaning but ultimately misguided effort to make a change. My former Lt. Governor Gavin Newsom once decided that MOOCs are the answer to education foes and is a way for CA to start giving $10K Bachelor’s degrees. The thinking was — let’s make a major change (a disruption!) to the old technology (teaching) in the style of Google, Uber and Theranos!
Lo and behold, California spent millions and went nowhere. Our collective teaching experience during COVID shows that this was not an accident or mismanagement. My current Governor, the very same Gavin Newsom, dropped this idea like a rock, limiting it to cosmetic changes. Note that this isn’t to say that online education is hopeless. In fact, see this old blog post where I offer some suggestions.
My modest proposal
The following suggestions are limited to pure math. Other fields and sciences are much too foreign for me to judge.
(i) Introduce a very clearly defined quick opinion window of about 3-4 weeks. The referees asked for quick opinions can either decline or agree within 48 hours. It will only take them about 10-20 minutes to make an opinion based on the introduction, so give them a week to respond with 1-2 paragraphs. Collect 2-3 quick opinions. If as an editor you feel you need more, you are probably biased against the paper or the area, and are fishing for a negative opinion to have “quick reject“. This is a bit similar to the way Nature, Science, etc. deal with their submissions.
(ii) Make quick opinion requests anonymous. Request the reviewers to assess how the paper fits the journal (better, worse, on point, best submitted to another area to journals X, Y or Z, etc.) Adopt the practice of returning these opinions to the authors. Proceed to the second stage by mutual agreement. This is a bit similar to TCS which has authors use the feedback from the conference makes decisions about the journal or other conference submissions.
(iii) If the paper is rejected or withdrawn after the quick opinion stage, adopt the practice to send quick opinions to another journal where the paper is resubmitted. Don’t communicate the names of the reviewers — if the new editor has no trust in the first editor’s qualifications, let them collect their own quick opinions. This would protect the reviewers from their names going to multiple journals thus making their names semi-public.
(iv) The most selective journals should require that the paper not be available on the web during the quick opinion stage, and violators be rejected without review. Anonymous for one — anonymous for all! The three week long delay is unlikely to hurt anybody, and the journal submission email confirmation should serve as a solid certificate of a priority if necessary. Some people will try to game the system like give a talk with the same title as the paper or write a blog post. Then it’s on editor’s discretion what to do.
(v) In the second (actual review) stage, the referees should get papers with authors’ names and proceed per usual practice.
Happy New Year everyone!
How to start a paper?
Starting a paper is easy. That is, if you don’t care for the marketing, don’t want to be memorable, and just want to get on with the story and quickly communicate what you have proved. Fair enough.
But that only works when your story is very simple, as in “here is a famous conjecture which we solve in this paper”. You are implicitly assuming that the story of the conjecture has been told elsewhere, perhaps many times, so that the reader is ready to see it finally resolved. But if your story is more complicated, this “get to the point” approach doesn’t really work (and yes, I argue in this blog post and this article there is always a story). Essentially you need to prepare the reader for what’s to come.
In my “How to write a clear math paper” (see also my blog post) I recommend writing the Foreword — a paragraph or two devoted to philosophy underlying your work or a high level explanation of the key idea in your paper before you proceed to state the main result:
Consider putting in the Foreword some highly literary description of what you are doing. If it’s beautiful or sufficiently memorable, it might be quoted in other papers, sometimes on a barely related subject, and bring some extra clicks to your work. Feel free to discuss the big picture, NSF project outline style, mention some motivational examples in other fields of study, general physical or philosophical principles underlying your work, etc. There is no other place in the paper to do this, and I doubt referees would object if you keep your Foreword under one page. For now such discussions are relegated to surveys and monographs, which is a shame since as a result some interesting perspectives of many people are missing.
Martin Krieger has a similar idea which he discusses at length in his 2018 AMS Notices article Don’t Just Begin with “Let A be an algebra…” This convinced me that I really should follow his (and my own) advice.
So recently I took a stock of my open opening lines (usually, joint with coauthors), and found a mixed bag. I decided to list some of them below for your amusement. I included only those which are less closely related to the subject matter of the article, so might appeal to broader audience. I am grateful to all my collaborators which supported or at least tolerated this practice.
Combinatorics matters
Combinatorics has always been a battleground of tools and ideas. That’s why it’s so hard to do, or even define.
Combinatorial inequalities (2019)
The subject of enumerative combinatorics is both classical and modern. It is classical, as the basic counting questions go back millennia; yet it is modern in the use of a large variety of the latest ideas and technical tools from across many areas of mathematics. The remarkable successes from the last few decades have been widely publicized; yet they come at a price, as one wonders if there is anything left to explore. In fact, are there enumerative problems that cannot be resolved with existing technology?
Complexity problems in enumerative combinatorics (2018), see also this blog post.
Combinatorial sequences have been studied for centuries, with results ranging from minute properties of individual sequences to broad results on large classes of sequences. Even just listing the tools and ideas can be exhausting, which range from algebraic to bijective, to probabilistic and number theoretic. The existing technology is so strong, it is rare for an open problem to remain unresolved for more than a few years, which makes the surviving conjectures all the more interesting and exciting.
Pattern avoidance is not P-recursive (2015), see also this blog post.
In Enumerative Combinatorics, the results are usually easy to state. Essentially, you are counting the number of certain combinatorial objects: exactly, asymptotically, bijectively or otherwise. Judging the importance of the results is also relatively easy: the more natural or interesting the objects are, and the stronger or more elegant is the final formula, the better. In fact, the story or the context behind the results is usually superfluous since they speak for themselves.
Hook inequalities (2020)
Proof deconstruction
There are two schools of thought on what to do when an interesting combinatorial inequality is established. The first approach would be to treat it as a tool to prove a desired result. The inequality can still be sharpened or generalized as needed, but this effort is aimed with applications as the goal and not about the inequality per se.
The second approach is to treat the inequality as a result of importance in its own right. The emphasis then shifts to finding the “right proof” in an attempt to understand, refine or generalize it. This is where the nature of the inequality intervenes — when both sides count combinatorial objects, the desire to relate these objects is overpowering.
Effective poset inequalities (2022)
There is more than one way to explain a miracle. First, one can show how it is made, a step-by-step guide to perform it. This is the most common yet the least satisfactory approach as it takes away the joy and gives you nothing in return. Second, one can investigate away every consequence and implication, showing that what appears to be miraculous is actually both reasonable and expected. This takes nothing away from the miracle except for its shining power, and puts it in the natural order of things. Finally, there is a way to place the apparent miracle as a part of the general scheme. Even, or especially, if this scheme is technical and unglamorous, the underlying pattern emerges with the utmost clarity.
Hook formulas for skew shapes IV (2021)
In Enumerative Combinatorics, when it comes to fundamental results, one proof is rarely enough, and one is often on the prowl for a better, more elegant or more direct proof. In fact, there is a wide belief in multitude of “proofs from the Book”, rather than a singular best approach. The reasons are both cultural and mathematical: different proofs elucidate different aspects of the underlying combinatorial objects and lead to different extensions and generalizations.
Hook formulas for skew shapes II (2017)
Hidden symmetries
The phrase “hidden symmetries” in the title refers to coincidences between the numbers of seemingly different (yet similar) sets of combinatorial objects. When such coincidences are discovered, they tend to be fascinating because they reflect underlying algebraic symmetries — even when the combinatorial objects themselves appear to possess no such symmetries.
It is always a relief to find a simple combinatorial explanation of hidden symmetries. A direct bijection is the most natural approach, even if sometimes such a bijection is both hard to find and to prove. Such a bijection restores order to a small corner of an otherwise disordered universe, suggesting we are on the right path in our understanding. It is also an opportunity to learn more about our combinatorial objects.
Bijecting hidden symmetries for skew staircase shapes (2021)
Hidden symmetries are pervasive across the natural sciences, but are always a delight whenever discovered. In Combinatorics, they are especially fascinating, as they point towards both advantages and limitations of the tools. Roughly speaking, a combinatorial approach strips away much of the structure, be it algebraic, geometric, etc., while allowing a direct investigation often resulting in an explicit resolution of a problem. But this process comes at a cost — when the underlying structure is lost, some symmetries become invisible, or “hidden”.
Occasionally this process runs in reverse. When a hidden symmetry is discovered for a well-known combinatorial structure, it is as surprising as it is puzzling, since this points to a rich structure which yet to be understood (sometimes uncovered many years later). This is the situation of this paper.
Hidden symmetries of weighted lozenge tilings (2020)
Problems in Combinatorics
How do you approach a massive open problem with countless cases to consider? You start from the beginning, of course, trying to resolve either the most natural, the most interesting or the simplest yet out of reach special cases. For example, when looking at the billions and billions of stars contemplating the immense challenge of celestial cartography, you start with the closest (Alpha Centauri and Barnard’s Star), the brightest (Sirius and Canopus), or the most useful (Polaris aka North Star), but not with the galaxy far, far away.
Durfee squares, symmetric partitions and bounds on Kronecker coefficients (2022)
Different fields have different goals and different open problems. Most of the time, fields peacefully coexist enriching each other and the rest of mathematics. But occasionally, a conjecture from one field arises to present a difficult challenge in another, thus exposing its technical strengths and weaknesses. The story of this paper is our effort in the face of one such challenge.
Kronecker products, characters, partitions, and the tensor square conjectures (2016)
It is always remarkable and even a little suspicious, when a nontrivial property can be proved for a large class of objects. Indeed, this says that the result is “global”, i.e. the property is a consequence of the underlying structure rather than individual objects. Such results are even more remarkable in combinatorics, where the structures are weak and the objects are plentiful. In fact, many reasonable conjectures in the area fail under experiments, while some are ruled out by theoretical considerations.
Log-concave poset inequalities (2021)
Sometimes a conjecture is more than a straightforward claim to be proved or disproved. A conjecture can also represent an invitation to understand a certain phenomenon, a challenge to be confirmed or refuted in every particular instance. Regardless of whether such a conjecture is true or false, the advances toward resolution can often reveal the underlying nature of the objects.
On the number of contingency tables and the independence heuristic (2022)
Combinatorial Interpretations
Finding a combinatorial interpretation is an everlasting problem in Combinatorics. Having combinatorial objects assigned to numbers brings them depth and structure, makes them alive, sheds light on them, and allows them to be studied in a way that would not be possible otherwise. Once combinatorial objects are found, they can be related to other objects via bijections, while the numbers’ positivity and asymptotics can then be analyzed.
What is in #P and what is not? (2022)
Traditionally, Combinatorics works with numbers. Not with structures, relations between the structures, or connections between the relations — just numbers. These numbers tend to be nonnegative integers, presented in the form of some exact formula or disguised as probability. More importantly, they always count the number of some combinatorial objects.
This approach, with its misleading simplicity, led to a long series of amazing discoveries, too long to be recounted here. It turns out that many interesting combinatorial objects satisfy some formal relationships allowing for their numbers to be analyzed. More impressively, the very same combinatorial objects appear in a number of applications across the sciences.
Now, as structures are added to Combinatorics, the nature of the numbers and our relationship to them changes. They no longer count something explicit or tangible, but rather something ephemeral or esoteric, which can only be understood by invoking further results in the area. Even when you think you are counting something combinatorial, it might take a theorem or a even the whole theory to realize that what you are counting is well defined.
This is especially true in Algebraic Combinatorics where the numbers can be, for example, dimensions of invariant spaces, weight multiplicities or Betti numbers. Clearly, all these numbers are nonnegative integers, but as defined they do not count anything per se, at least in the most obvious or natural way.
What is a combinatorial interpretation? (2022)
Covering all bases
It is a truth universally acknowledged, that a combinatorial theory is often judged not by its intrinsic beauty but by the examples and applications. Fair or not, this attitude is historically grounded and generally accepted. While eternally challenging, this helps to keep the area lively, widely accessible, and growing in unexpected directions.
Hook formulas for skew shapes III (2019)
In the past several decades, there has been an explosion in the number of connections and applications between Geometric and Enumerative Combinatorics. Among those, a number of new families of “combinatorial polytopes” were discovered, whose volume has a combinatorial significance. Still, whenever a new family of n-dimensional polytopes is discovered whose volume is a familiar integer sequence (up to scaling), it feels like a “minor miracle”, a familiar face in a crowd in a foreign country, a natural phenomenon in need of an explanation.
Triangulations of Cayley and Tutte polytopes (2013)
The problem of choosing one or few objects among the many has a long history and probably existed since the beginning of human era (e.g. “Choose twelve men from among the people” Joshua 4:2). Historically this choice was mostly rational and random choice was considered to be a bad solution. Times have changed, however. [..] In many cases random solution has become desirable, if not the only possibility. Which means that it’s about time we understand the nature of a random choice.
When and how n choose k (1996)
Books are ideas
In his famous 1906 “white suit” speech, Mark Twain recalled a meeting before the House of Lords committee, where he argued in favor of perpetual copyright. According to Twain, the chairman of the committee with “some resentment in his manner,” countered: “What is a book? A book is just built from base to roof on ideas, and there can be no property in it.”
Sidestepping the copyright issue, the unnamed chairman had a point. In the year 2021, in the middle of the pandemic, books are ideas. They come in a variety of electronic formats and sizes, they can be “borrowed” from the “cloud” for a limited time, and are more ephemeral than long lasting. Clinging to the bygone era of safety and stability, we just keep thinking of them as sturdy paper volumes.
When it comes to math books, the ideas are fundamental. Really, we judge them largely based on the ideas they present, and we are willing to sacrifice both time and effort to acquire these ideas. In fact, as a literary genre, math books get away with a slow uninventive style, dull technical presentation, anticlimactic ending, and no plot to speak of. The book under review is very different. [..]
See this books review and this blog post (2021).
Warning: This post is not meant to be a writing advice. The examples I give are merely for amusement purposes and definitely not be emulated. I am happy with some of these quotes and a bit ashamed of others. Upon reflection, the style is overly dramatic most likely because I am overcompensating for something. But hey — if you are still reading this you probably enjoyed it…
How I chose Enumerative Combinatorics
Apologies for not writing anything for awhile. After Feb 24, the math part of the “life and math” slogan lost a bit of relevance, while the actual events were stupefying to the point when I had nothing to say about the life part. Now that the shock subsided, let me break the silence by telling an old personal story which is neither relevant to anything happening right now nor a lesson to anyone. Sometimes a story is just a story…
My field
As the readers of this blog know, I am a Combinatorialist. Not a “proud one”. Just “a combinatorialist”. To paraphrase a military slogan “there are many fields like this one, but this one is mine”. While I’ve been defending my field for years, writing about its struggles, and often defining it, it’s not because this field is more important than others. Rather, because it’s so frequently misunderstood.
In fact, I have worked in other (mostly adjacent) fields, but that was usually because I was curious. Curious what’s going on in other areas, curious if they had tools to help me with my problems. Curious if they had problems that could use my tools. I would go to seminars in other fields, read papers, travel to conferences, make friends. Occasionally this strategy paid off and I would publish something in another field. Much more often nothing ever came out of that. It was fun regardless.
Anyway, I wanted to work in combinatorics for as long as I can remember, since I was about 15 or so. There is something inherently discrete about the way I see the world, so much that having additional structure is just obstructing the view. Here is how Gian-Carlo Rota famously put it:
Combinatorics is an honest subject. […] You either have the right number or you haven’t. You get the feeling that the result you have discovered is forever, because it’s concrete. [Los Alamos Science, 1985]
I agree. Also, I really like to count. When prompted, I always say “I work in Combinatorics” even if sometimes I really don’t. But in truth, the field is much too large and not unified, so when asked to be more specific (this rarely happens) I say “Enumerative Combinatorics“. What follows is a short story of how I made the choice.
Family vacation
When I was about 18, Andrey Zelevinsky (ז״ל) introduced me and Alex Postnikov to Israel Gelfand and asked what should we be reading if we want to do combinatorics. Unlike most leading mathematicians in Russia, Gelfand had a surprisingly positive view on the subject (see e.g. his quotes here). He suggested we both read Macdonald’s book, which was translated into Russian by Zelevinsky himself just a few years earlier. The book was extremely informative but dry as a fig and left little room for creativity. I read a large chunk of it and concluded that if this is what modern combinatorics looks like, I want to have nothing to do with it. Alex had a very different impression, I think.
Next year, my extended family decided to have a vacation on a Russian “river cruise”. I remember a small passenger boat which left Moscow river terminal, navigated a succession of small rivers until it reached Volga. From there, the boat had a smooth gliding all the way to the Caspian Sea. The vacation was about three weeks of a hot Summer torture with the only relief served by mouth-watering fresh watermelons.
What made it worse, there was absolutely nothing to see. Much of the way Volga is enormously wide, sometimes as wide as the English channel. Most of the time you couldn’t even see the river banks. The cities distinguished themselves only by an assortment of Lenin statues, but were unremarkable otherwise. Volgograd was an exception with its very impressive tallest statue in Europe, roughly as tall as the Statue of Liberty when combined with its pedestal. Impressive for sure, but not worth the trip. Long story short, the whole cruise vacation was dreadfully boring.
One good book can make a difference
While most of my relatives occupied themselves by reading crime novels or playing cards, I was reading a math book, the only book I brought with me. This was Stanley’s Enumerative Combinatorics (vol. 1) whose Russian translation came out just a few months earlier. So I read it cover-to-cover, but doing only the easiest exercises just to make sure I understand what’s going on. That book changed everything…
Midway through, when I was reading about linear extensions of posets in Ch. 3 with their obvious connections to standard Young tableaux and the hook-length formula (which I already knew by then), I had an idea. From Macdonald’s book, I remembered the q-analogue of #SYT via the “charge“, a statistics introduced by Lascoux and Schützenberger to give a combinatorial interpretation of Kostka polynomials, and which works even for skew Young diagram shapes. I figured that skew shapes are generic enough, and there should be a generalization of the charge to all posets. After several long days filled with some tedious calculations by hand, I came up with both the statement and the proof of the q-analogue of the number of linear extensions.
I wrote the proof neatly in my notebook with a clear intent to publish my “remarkable discovery”, and continued reading. In Ch. 4, all of a sudden, I read the “P-partition theory” that I just invented by myself. It came with various applications and connections to other problems, and was presented so well, much nicer than I would have!
After some extreme disappointment, I learned from the notes that the P-partition theory was a large portion of Stanley’s own Ph.D. thesis, which he wrote before I was born. For a few hours, I did nothing but meditate, staring at the vast water surrounding me and ignoring my relatives who couldn’t care less what I was doing anyway. I was trying to think if there is a lesson in this fiasco.
It pays to be positive and self-assure, I suppose, in a way that only a teenager can be. That day I concluded that I am clearly doing something right, definitely smarter than everyone else even if born a little too late. More importantly, I figured that Enumerative Combinatorics done “Stanley-style” is really the right area for me…
Epilogue
I stopped thinking that I am smarter than everyone else within weeks, as soon as I learned more math. I no longer believe I was born too late. I did end up doing a lot of Enumerative Combinatorics. Much later I became Richard Stanley’s postdoc for a short time and a colleague at MIT for a long time. Even now, I continue writing papers on the numbers of linear extensions and standard Young tableaux. Occasionally, I also discuss their q-analogues (like in my most recent paper). I still care and it’s still the right area for me…
Some years later I realized that historically, the “charge” and Stanley’s q-statistics were not independent in a sense that both are generalizations of the major index by Percy MacMahon. In his revision of vol. 1, Stanley moved the P-partition theory up to Ch. 3, where it belongs IMO. In 2001, he received the Steele’s Prize for Mathematical Exposition for the book that changed everything…
The problem with combinatorics textbooks
Every now and then I think about writing a graduate textbook in Combinatorics, based on some topics courses I have taught. I scan my extensive lecture notes, think about how much time it would take, and whether there is even a demand for this kind of effort. Five minutes later I would always remember that YOLO, deeply exhale and won’t think about it for a while.
What’s wrong with Combinatorics?
To illustrate the difficulty, let me begin with two quotes which contradict each other in the most illuminating way. First, from the Foreword by Richard Stanley on (his former student) Miklós Bóna’s “A Walk Through Combinatorics” textbook:
The subject of combinatorics is so vast that the author of a textbook faces a difficult decision as to what topics to include. There is no more-or-less canonical corpus as in such other subjects as number theory and complex variable theory. [here]
Second, from the Preface by Kyle Petersen (and Stanley’s academic descendant) in his elegant “Inquiry-Based Enumerative Combinatorics” textbook:
Combinatorics is a very broad subject, so the difficulty in writing about the subject is not what to include, but rather what to exclude. Which hundred problems should we choose? [here]
Now that this is all clear, you can probably insert your own joke about importance of teaching inclusion-exclusion. But I think the issue is a bit deeper than that.
I’ve been thinking about this when updating my “What is Combinatorics” quotation page (see also my old blog post on this). You can see a complete divergence of points of view on how to answer this question. Some make the definition or description to be very broad (sometimes even ridiculously broad), some relatively narrow, some are overly positive, while others are revoltingly negative. And some basically give up and say, in effect “it is what it is”. This may seem puzzling, but if you concentrate on the narrow definitions and ignore the rest, a picture emerges.
Clearly, these people are not talking about the same area. They are talking about sub-areas of Combinatorics that they know well, that they happen to learn or work on, and that they happen to like or dislike. Somebody made a choice what part of Combinatorics to teach them. They made a choice what further parts of Combinatorics to learn. These choices are increasingly country or culture dependent, and became formative in people’s mind. And they project their views of these parts of Combinatorics on the whole field.
So my point is — there is no right answer to “What is Combinatorics?“, in a sense that all these opinions are biased to some degree by personal education and experience. Combinatorics is just too broad of a category to describe. It’s a bit like asking “what is good food?” — the answers would be either broad and bland, or interesting but very culture-specific.
Courses and textbooks
How should one resolve the issue raised above? I think the answer is simple. Stop claiming that Combinatorics, or worse, Discrete Mathematics, is one subject. That’s not true and hasn’t been true for a while. I talked about this in my “Unity of Combinatorics” book review. Combinatorics is comprised of many sub-areas, see the Wikipedia article I discussed here (long ago). Just accept it.
As a consequence, you should never teach a “Combinatorics” course. Never! Especially to graduate students, but to undergraduates as well. Teach courses in any and all of these subjects: Enumerative Combinatorics, Graph Theory, Probabilistic Combinatorics, Discrete Geometry, Algebraic Combinatorics, Arithmetic Combinatorics, etc. Whether introductory or advanced versions of these courses, there is plenty of material for each such course.
Stop using these broad “a little bit about everything” combinatorics textbooks which also tend to be bulky, expensive and shallow. It just doesn’t make sense to teach both the five color theorem and the Catalan numbers (see also here) in the same course. In fact, this is a disservice to both the students and the area. Different students want to know about different aspects of Combinatorics. Thus, if you are teaching the same numbered undergraduate course every semester you can just split it into two or three, and fix different syllabi in advance. The students will sort themselves out and chose courses they are most interested in.
My own teaching
At UCLA, with the help of the Department, we split one Combinatorics course into two titled “Graph Theory” and “Enumerative Combinatorics”. They are broader, in fact, than the titles suggest — see Math 180 and Math 184 here. The former turned out to be quite a bit more popular among many applied math and non-math majors, especially those interested in CS, engineering, data science, etc., but also from social sciences. Math majors tend to know a lot of this material and flock to the latter course. I am not saying you should do the same — this is just an example of what can be done.
I remember going through a long list of undergraduate combinatorics textbooks a few years ago, and found surprisingly little choice for the enumerative/algebraic courses. Of the ones I liked, let me single out Bóna’s “Introduction to Enumerative and Analytic Combinatorics“ and Stanley’s “Algebraic Combinatorics“. We now use both at UCLA. There are also many good Graph Theory course textbooks of all levels, of course.
Similarly, for graduate courses, make sure you make the subject relatively narrow and clearly defined. Like a topics class, except accessible to beginning graduate students. Low entry barrier is an advantage Combinatorics has over other areas, so use it. To give examples from my own teaching, see unedited notes from my graduate courses:
Combinatorics of posets (Fall 2020)
Combinatorics and Probability on groups (Spring 2020)
Algebraic Combinatorics (Winter 2019)
Discrete and Polyhedral Geometry (Fall 2018) This is based on my book. See also videos of selected topics (in Russian).
Combinatorics of Integer Sequences (Fall 2016)
Combinatorics of Words (Fall 2014)
Tilings (Winter 2013, lecture-by-lecture refs only)
In summary
In my experience, the more specific you make the combinatorics course the more interesting it is to the students. Don’t be afraid that the course would appear be too narrow or too advanced. That’s a stigma from the past. You create a good course and the students will quickly figure it out. They do have their own FB and other chat groups, and spread the news much faster than you could imagine…
Unfortunately, there is often no good textbook to cover what you want. So you might have to work a little harder harder to scout the material from papers, monographs, etc. In the internet era this is easier than ever. In fact, many extensive lecture notes are already available on the web. Eventually, all the appropriate textbooks will be written. As I mentioned before, this is one of the very few silver linings of the pandemic…
P.S. (July 8, 2021) I should have mentioned that in addition to “a little bit about everything” textbooks, there are also “a lot about everything” doorstopper size volumes. I sort of don’t think of them as textbooks at all, more like mixtures of a reference guide, encyclopedia and teacher’s manual. Since even the thought of teaching from such books overwhelms the senses, I don’t expect them to be widely adopted.
Having said that, these voluminous textbooks can be incredibly valuable to both the students and the instructor as a source of interesting supplementary material. Let me single out an excellent recent “Combinatorial Mathematics” by Doug West written in the same clear and concise style as his earlier “Introduction to Graph Theory“. Priced modestly (for 991 pages), I recommend it as “further reading” for all combinatorics courses, even though I strongly disagree with the second sentence of the Preface, per my earlier blog post.
Why you shouldn’t be too pessimistic
In our math research we make countless choices. We chose a problem to work on, decide whether its claim is true or false, what tools to use, what earlier papers to study which might prove useful, who to collaborate with, which computer experiments might be helpful, etc. Choices, choices, choices… Most our choices are private. Others are public. This blog is about wrong public choices that I made misjudging some conjectures by being overly pessimistic.
The meaning of conjectures
As I have written before, conjectures are crucial to the developments of mathematics and to my own work in particular. The concept itself is difficult, however. While traditionally conjectures are viewed as some sort of “unproven laws of nature“, that comparison is widely misleading as many conjectures are descriptive rather than quantitative. To understand this, note the stark contrast with experimental physics, as many mathematical conjectures are not particularly testable yet remain quite interesting. For example, if someone conjectures there are infinitely many Fermat primes, the only way to dissuade such person is to actually disprove the claim.
There is also an important social aspect of conjecture making. For a person who poses a conjecture, there is a certain clairvoyance respected by other people in the area. Predictions are never easy, especially of a precise technical nature, so some bravery or self-assuredness is required. Note that social capital is spent every time a conjecture is posed. In fact, a lot of it is lost when it’s refuted, you come out even if it’s proved relatively quickly, and you gain only if the conjecture becomes popular or proved possibly many years later. There is also a “boy who cried wolf” aspect for people who make too many conjectures of dubious quality — people will just tune out.
Now, for the person working on a conjecture, there is also a betting aspect one cannot ignore. As in, are you sure you are working in the right direction? Perhaps, the conjecture is simply false and you are wasting your time… I wrote about this all before in the post linked above, and the life/career implications on the solver are obvious. The success in solving a well known conjecture is often regarded much higher than a comparable result nobody asked about. This may seem unfair, and there is a bit of celebrity culture here. Thinks about it this way — two lead actors can have similar acting skills, but the one who is a star will usually attract a much larger audience…
Stories of conjectures
Not unlike what happens to papers and mathematical results, conjectures also have stories worth telling, even if these stories are rarely discussed at length. In fact, these “conjecture stories” fall into a few types. This is a little bit similar to the “types of scientific papers” meme, but more detailed. Let me list a few scenarios, from the least to the most mathematically helpful:
(1) Wishful thinking. Say, you are working on a major open problem. You realize that a famous conjecture A follows from a combination of three conjectures B, C and D whose sole motivation is their applications to A. Some of these smaller conjectures are beyond the existing technology in the area and cannot be checked computationally beyond a few special cases. You then declare that this to be your “program” and prove a small special case of C. Somebody points out that D is trivially false. You shrug, replace it with a weaker D’ which suffices for your program but is harder to disprove. Somebody writes a long state of the art paper disproving D’. You shrug again and suggest an even weaker conjecture D”. Everyone else shrugs and moves on.
(2) Reconfirming long held beliefs. You are working in a major field of study aiming to prove a famous open problem A. Over the years you proved a number of special cases of A and became one the leaders of the area. You are very optimistic about A discussing it in numerous talks and papers. Suddenly A is disproved in some esoteric situations, undermining the motivation of much of your older and ongoing work. So you propose a weaker conjecture A’ as a replacement for A in an effort to salvage both the field and your reputation. This makes happy everyone in the area and they completely ignore the disproof of A from this point on, pretending it’s completely irrelevant. Meanwhile, they replace A with A’ in all subsequent papers and beamer talk slides.
(3) Accidental discovery. In your ongoing work you stumble at a coincidence. It seem, all objects of a certain kind have some additional property making them “nice“. You are clueless why would that be true, since being nice belongs to another area X. Being nice is also too abstract to be checked easily on a computer. You consult a colleague working in X whether this is obvious/plausible/can be proved and receive No/Yes/Maybe answers to these three questions. You are either unable to prove the property or uninterested in problem, or don’t know much about X. So you mention it in the Final Remarks section of your latest paper in vain hope somebody reads it. For a few years, every time you meet somebody working in X you mention to them your “nice conjecture”, so much that people laugh at you behind your back.
(4) Strong computational evidence. You are doing computer experiments related to your work. Suddenly certain numbers appear to have an unexpectedly nice formula or a generating function. You check with OEIS and the sequence is there indeed, but not with the meaning you wanted. You use the “scientific method” to get a few more terms and they indeed support your conjectural formula. Convinced this is not an instance of the “strong law of small numbers“, you state the formula as a conjecture.
(5) Being contrarian. You think deeply about famous conjecture A. Not only your realize that there is no way one can approach A in full generality, but also that it contradicts some intuition you have about the area. However, A was stated by a very influential person N and many people believe in A proving it in a number of small special cases. You want to state a non-A conjecture, but realize the inevitable PR disaster of people directly comparing you to N. So you either state that you don’t believe in A, or that you believe in a conjecture B which is either slightly stronger or slightly weaker than non-A, hoping the history will prove you right.
(6) Being inspirational. You think deeply about the area and realize that there is a fundamental principle underlying certain structures in your work. Formalizing this principle requires a great deal of effort and results in a conjecture A. The conjecture leads to a large body of work by many people, even some counterexamples in esoteric situations, leading to various fixes such as A’. But at that point A’ is no longer the goal but more of a direction in which people work proving a number of A-related results.
Obviously, there are many other possible stories, while some stories are are a mixture of several of these.
Why do I care? Why now?
In the past few years I’ve been collecting references to my papers which solve or make some progress towards my conjectures and open problems, putting links to them on my research page. Turns out, over the years I made a lot of those. Even more surprisingly, there are quite a few papers which address them. Here is a small sampler, in random order:
(1) Scott Sheffield proved my ribbon tilings conjecture.
(2) Alex Lubotzky proved my conjecture on random generation of a finite group.
(3) Our generalized loop-erased random walk conjecture (joint with Igor Gorodezky) was recently proved by Heng Guo and Mark Jerrum.
(4) Our Young tableau bijections conjecture (joint with Ernesto Vallejo) was resolved by André Henriques and Joel Kamnitzer.
(5) My size Ramsey numbers conjecture led to a series of papers, and was completely resolved only recently by Nemanja Draganić, Michael Krivelevich and Rajko Nenadov.
(6) One of my partition bijection problems was resolved by Byungchan Kim.
The reason I started collecting these links is kind of interesting. I was very impressed with George Lusztig and Richard Stanley‘s lengthy writeups about their collected papers that I mentioned in this blog post. While I don’t mean to compare myself to these giants, I figured the casual reader might want to know if a conjecture in some paper had been resolved. Thus the links on my website. I recommend others also do this, as a navigational tool.
What gives?
Well, looks like none of my conjectures have been disproved yet. That’s a good news, I suppose. However, by going over my past research work I did discover that on three occasions when I was thinking about other people’s conjectures, I was much too negative. This is probably the result of my general inclination towards “negative thinking“, but each story is worth telling.
(i) Many years ago, I spent some time thinking about Babai’s conjecture which states that there are universal constants C, c >0, such that for every simple group G and a generating set S, the diameter of the Cayley graph Cay(G,S) is at most C(log |G|)c. There has been a great deal of work on this problem, see e.g. this paper by Sean Eberhard and Urban Jezernik which has an overview and references.
Now, I was thinking about the case of the symmetric group trying to apply arithmetic combinatorics ideas and going nowhere. In my frustration, in a talk I gave (Galway, 2009), I wrote on the slides that “there is much less hope” to resolve Babai’s conjecture for An than for simple groups of Lie type or bounded rank. Now, strictly speaking that judgement was correct, but much too gloomy. Soon after, Ákos Seress and Harald Helfgott proved a remarkable quasi-polynomial upper bound in this case. To my embarrassment, they referenced my slides as a validation of the importance of their work.
Of course, Babai’s conjecture is very far from being resolved for An. In fact, it is possible that the diameter is always O(n2). We just have no idea. For simple groups of Lie type or large rank the existing worst case diameter bounds are exponential and much too weak compared to the desired bound. As Eberhard and Jezernik amusingly wrote in the paper linked above, “we are still exponentially stupid“…
(ii) When he was my postdoc at UCLA, Alejandro Morales told me about a curious conjecture in this paper (Conjecture 5.1), which claimed that the number of certain nonsingular matrices over the finite field Fq is polynomial in q with positive coefficients. He and coauthors proved the conjecture is some special cases, but it was wide open in full generality.
Now, I thought about this type of problems before and was very skeptical. I spent a few days working on the problem to see if any of my tools can disprove it, and failed miserably. But in my stubbornness I remained negative and suggested to Alejandro that he should drop the problem, or at least stop trying to prove rather than disprove the conjecture. I was wrong to do that.
Luckily, Alejandro ignored my suggestion and soon after proved the polynomial part of the conjecture together with Joel Lewis. Their proof is quite elegant and uses certain recurrences coming from the rook theory. These recurrences also allow a fast computation of these polynomials. Consequently, the authors made a number of computer experiments and disproved the positivity of coefficients part of the conjecture. So the moral is not to be so negative. Sometimes you need to prove a positive result first before moving to the dark side.
(iii) The final story is about the beautiful Benjamini conjecture in probabilistic combinatorics. Roughly speaking, it says that for every finite vertex transitive graph G on n vertices and diameter O(n/log n) the critical percolation constant pc <1. More precisely, the conjecture claims that there is p<1-ε, such that a p-percolation on G has a connected component of size >n/2 with probability at least δ, where constants ε, δ>0 depend on the constant implied by the O(*) notation, but not on n. Here by “p-percolation” we mean a random subgraph of G with probability p of keeping and 1-p of deleting an edge, independently for all edges of G.
Now, Itai Benjamini is a fantastic conjecture maker of the best kind, whose conjectures are both insightful and well motivated. Despite the somewhat technical claim, this conjecture is quite remarkable as it suggested a finite version of the “pc<1″ phenomenon for infinite groups of superlinear growth. The latter is the famous Benjamini–Schramm conjecture (1996), which was recently proved in a remarkable breakthrough by Hugo Duminil-Copin, Subhajit Goswami, Aran Raoufi, Franco Severo and Ariel Yadin. While I always believed in that conjecture and even proved a tiny special case of it, finite versions tend to be much harder in my experience.
In any event, I thought a bit about the Benjamini conjecture and talked to Itai about it. He convinced me to work on it. Together with Chis Malon, we wrote a paper proving the claim for some Cayley graphs of abelian and some more general classes of groups. Despite our best efforts, we could not prove the conjecture even for Cayley graphs of abelian groups in full generality. Benjamini noted that the conjecture is tight for products of two cyclic groups, but that justification did not sit well with me. There seemed to be no obvious way to prove the conjecture even for the Cayley graph of Sn generated by a transposition and a long cycle, despite the very small O(n2) diameter. So we wrote in the introduction: “In this paper we present a number of positive results toward this unexpected, and, perhaps, overly optimistic conjecture.”
As it turns out, it was us who were being overly pessimistic, even if we never actually stated that we believe the conjecture is false. Most recently, in an amazing development, Tom Hutchcroft and Matthew Tointon proved a slightly weaker version of the conjecture by adapting the methods of Duminil-Copin et al. They assume the O(n/(log n)c) upper bound on the diameter which they prove is sufficient, for some universal constant c>1. They also extend our approach with Malon to prove the conjecture for all Cayley graphs of abelian groups. So while the Benjamini conjecture is not completely resolved, my objections to it are no longer valid.
Final words on this
All in all, it looks like I was never formally wrong even if I was a little dour occasionally (Yay!?). Turns out, some conjectures are actually true or at least likely to hold. While I continue to maintain that not enough effort is spent on trying to disprove the conjectures, it is very exciting when they are proved. Congratulations to Harald, Alejandro, Joel, Tom and Matthew, and posthumous congratulations to Ákos for their terrific achievements!
The Unity of Combinatorics
I just finished my very first book review for the Notices of the AMS. The authors are Ezra Brown and Richard Guy, and the book title is the same as the blog post. I had mixed feelings when I accepted the assignment to write this. I knew this would take a lot of work (I was wrong — it took a huge amount of work). But the reason I accepted is because I strongly suspected that there is no “unity of combinatorics”, so I wanted to be proved wrong. Here is how the book begins:
One reason why Combinatorics has been slow to become accepted as part of mainstream Mathematics is the common belief that it consists of a bag of isolated tricks, a number of areas: [very long list – IP] with little or no connection between them. We shall see that they have numerous threads weaving them together into a beautifully patterned tapestry.
Having read the book, I continue to maintain that there is no unity. The book review became a balancing act — how do you write a somewhat positive review if you don’t believe into the mission of the book? Here is the first paragraph of the portion of the review where I touch upon themes very familiar to readers of this blog:
As I see it, the whole idea of combinatorics as a “slow to become accepted” field feels like a throwback to the long forgotten era. This attitude was unfair but reasonably common back in 1970, outright insulting and relatively uncommon in 1995, and was utterly preposterous in 2020.
After a lengthy explanation I conclude:
To finish this line of thought, it gives me no pleasure to conclude that the case for the unity of combinatorics is too weak to be taken seriously. Perhaps, the unity of mathematics as a whole is an easier claim to establish, as evident from [Stanley’s] quotes. On the other hand, this lack of unity is not necessarily a bad thing, as we would be amiss without the rich diversity of cultures, languages, open problems, tools and applications of different areas.
Enjoy the full review! And please comment on the post with your own views on this alleged “unity”.
P.S. A large part of the book is freely downloadable. I made this website for the curious reader.
Remark (ADDED April 17, 2021)
Ezra “Bud” Brown gave a talk on the book illustrating many of the connections I discuss in the review. This was at a memorial conference celebrating Richard Guy’s legacy. I was not aware of the video until now. Watch the whole talk.
2021 Abel Prize
I am overjoyed with the news of the Abel prize awarded to László Lovász and Avi Wigderson. You can now see three (!) Abel laureates discussing Combinatorics — follow the links in this blog post from 2019. See also Gil Kalai’s blog post for further links to lectures.

{kind=link}
{kind=link}
{kind=link}
You must be logged in to post a comment.