Archive
Computational combinatorics
Say, you have written a paper. You want to submit it to a journal. But in what field? More often than not, the precise field/area designation for this paper is easy to determine, or at least easy to place it into some large category. Even if the paper is in between fields, this is often well regarded and understood situation, nothing wrong with that. Say, the paper is resolving a problem in field X with tools from field Y. Submit to X-journal unless the application is routine and the crux of the innovation is in refining the tools. Then submit to Y-journal.
However, when it comes to CS, things are often less clear. This is in part because of the novelty of the subject, and in part due to the situation in CS theory, which is in constant flux and search for direction (a short Wikipedia article is as rather vague and unhelpful, even more so than these generic WP articles tend to be).
The point of this post is to introduce/describe the area of “Computational Combinatorics“. Although Google returns 20K hits for this term (including experts, courses, textbooks), the meaning is either obscure or misleading. We want to clarify what we mean, critique everyone else, and make a stake for the term!
1) What I want computational combinatorics to mean is “theoretical CS aspects of combinatorics” (and to a lesser extend “practical..”), which is essentially part of combinatorics but the tools and statements use compute science terminology (for a concise description of complexity aspects, see dated but excellent survey by David Shmoys and Eva Tardos). I will give a recent example below, but basically if you want to prove a negative result in combinatorics (as in “one should not expect a nice formula for the number of 3-colorings or perfect matchings of a general graph”), then CS language (and basic tools) is a way to go. When people use “computational combinatorics” to mean “basic results in combinatorics that are useful for further studies of computer science”, they are being misleading. A proper name for such course is “Introduction to Combinatorics” or “Combinatorics for Computer Scientists”, etc.
2) In two recent papers, Jed Yang and I proved several complexity results on tilings. To explain them, let me start with the following beautiful result by Éric Rémila, built on earlier papers by Thurston, Conway & Lagarias, and Kenyon & Kenyon:
Tileability of a simply connected region in the plane with two types of rectangles can be decided in polynomial time.
First, we show that when the number of rectangles is sufficiently large (originally about 106, later somewhat decreased), one should not expect such a result. Formally, we prove that tileability is NP-hard in this case. We then show that in 3-dim the topology of the region gives no advantage. Among other results, we prove that tileability of contractible regions with 2x2x1 slabs is
NP-complete, and counting 2x1x1 domino tilings of contractible regions is #P-complete.
Now, the CS Theory point of view on these types of results changed drastically over time. Roughly, 30 years ago they were mainstream. About 20 years ago they were still of interest, but no longer important. Nowadays they are marginal at best – the field has moved on. My point is that the result are of interest in Combinatorics and Combinatorics only. Indeed, it has long been observed that applying combinatorial group theory to tilings (as done by Thurston, Rémila, etc.) is more of an art than a science. Although we believe that already for three general rectangles in the plane the problem is intractable, proving such a result is exceedingly difficult. Our various results solve weak versions of this problem.
3) The ontology (classification) in mathematics has always been a mess (this is not unusual). For example, combinatorial enumeration is the same as enumerative combinatorics. On the other hand, as far as I can tell, analytic geometry has nothing to do with geometric analysis. There is also no “monotonicity” to speak about: even though group theory is a part of algebra, the geometric group theory is neither a part of geometric algebra, nor of algebraic geometry, although traditionally contains combinatorial group theory. Distressingly, there are two completely different (competing) notions of “algebraic combinatorics” (see here and there), and algebraic graph theory which is remarkably connected to both of these. The list goes on.
4) So, why name a field at all, given the mess we have? That’s mostly because we really want to incorporate the CS aspects of combinatorics as a legitimate branch of mathematics. Theory CS is already over the top combinatorial (check out the number of people who believe that P=?NP will be resolved with combinatorics), but when a problem arises in combinatorics from within, this part of combinatorics needs a name to call home. I propose using the term computational combinatorics, in line with computational group theory, computational geometry, computational topology, etc., as a part of the loosely defined computational mathematics. I feel that the adjective “computational” is broad and flexible enough to incorporate both theoretical/complexity aspects as well as some experimental work, and combinatorial software development (as in WZ theory), compared to other adjectives, such as “algorithmic”, “computable”, “effective”, “computer-sciency”, etc. So, please, AMS, next time you revise your MSC, consider adding “Computational Combinatorics” as 05Fxx.
P.S. A well known petition asks for graph theory to have its own MSC code (specifically, 07), due to the heavy imbalance in the number of graph theory vs. the rest of combinatorics papers. Without venturing an opinion, let me mention that perhaps, adding a top level “computational combinatorics” subfield of combinatorics will remedy this as well – surely some papers will migrate there from graph theory. Just a thought…
A lost bijection
One can argue whether some proofs are from the book, while others maybe not. Some such proofs are short but non-elementary, others are elementary but slightly tedious, yet others are short but mysterious, etc. (see here for these examples). BTW, can one result have two or more “proofs from the book”?
However, very occasionally you come across a proof that is both short, elementary and completely straightforward. One would call such a proof trivial, if not for the fact that it’s brand new. I propose a new term for these – let’s call them lost proofs, loosely defined as proofs which should have been discovered decades or centuries ago, but evaded this fate for whatever accidental historical circumstances (as in lost world, get it?) And when you find such a proof you sort of can’t believe it. Really? This is true? This is new? Really? Really?!?
Let me describe one such lost proof. This story started in 1857 when Arthur Cayley wrote “On a problem in the partition of numbers”, with the following curious result:
The number of integer sequences
such that
, and
for
, is equal to the total number of partitions of integers
into parts
.
For example, for 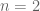
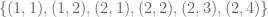

This result was discovered about 20-25 years too soon. In 1879-1882, while at Johns Hopkins University, Sylvester pioneered what he called a “constructive partition theory”, and had he seen his good friend’s older paper, he probably would have thought about finding a bijective proof. Apparently, he didn’t. In all fairness to everybody involved, Cayley had written over 900 papers.
Now, the problem was rediscovered by Minc (1959), and notably by Andrews, Paule, Riese and Strehl (2001) as a biproduct of computer experiments. Both Cayley’s and APRS’s proofs are analytic (using generating functions). More recent investigations by Corteel, Lee and Savage (2005 and 2007 papers), and Beck, Braun and Le (2011) proved various extensions, still using generating functions.
We are now ready for the “lost proof”, which is really a lost bijection. It’s given by just one formula, due to Matjaž Konvalinka and me:
![\Psi: (a_1,a_2,a_3,\ldots,a_n) \to [2^{n-1}]^{2-a_1} [2^{n-2}]^{2a_1-a_2}[2^{n-3}]^{2a_2-a_3} \ldots 1^{2a_{n-1}-a_n}](https://s0.wp.com/latex.php?latex=%5CPsi%3A+%28a_1%2Ca_2%2Ca_3%2C%5Cldots%2Ca_n%29+%5Cto+%5B2%5E%7Bn-1%7D%5D%5E%7B2-a_1%7D+%5B2%5E%7Bn-2%7D%5D%5E%7B2a_1-a_2%7D%5B2%5E%7Bn-3%7D%5D%5E%7B2a_2-a_3%7D+%5Cldots+1%5E%7B2a_%7Bn-1%7D-a_n%7D&bg=ffffff&fg=555555&s=0&c=20201002)
For example, for

Of course, once the bijection is found, the proof of Cayley’s theorem is completely straightforward. Also, once you have such an affine formula, many extensions become trivial.
One wonders, how does one can come up with such a bijection. The answer is: simply compute it assuming there is an affine map. It tends to be unique. Also, we have done this before (for convex partitions and LR-coefficients). There is a reason why this bijection is so similar to Sylvie Corteel’s “brilliant human-generated one-line proof” in the words of Doron Zeilberger. So it’s just amazing that this simple proof has been “lost” for over 150 years, until now…
See our paper (Konvalinka and Pak, “Cayley compositions, partitions, polytopes, and geometric bijections”, 2012) for applications of this “lost bijection” and my survey (Pak, “Partition Bijections, a Survey”, 2006) for more on partition bijections.
